

Reporting API migration guide
Review the changes for the latest version of Soda Cloud's Reporting API and learn how to migrate existing calls.
Version 1: New and changed
Version 1 of the reporting API (Preview) retrieves all of its data from pre-processed and aggregated data sources. This change addresses the issue of application performance impact in v0 when deriving some metrics "on the fly", such as health and coverage.
The reporting API refreshes the data for all endpoints once per day between 10:00pm and 11:00pm EST. This update frequency may increase in the future if the need for intra-day reporting arises.
Tests in Soda products have been renamed checks. Therefore, any references to
testsin the Reporting API now exist aschecks.Most endpoints use pagination. Refer to Pagination subsection below for details.
There is one new endpoint: Platform impact: Incidents endpoint
The following endpoints have query and response-breaking code changes. Refer to subsections below for details.
The following endpoints are deprecated:
/adoption/sign_ups/adoption/sign_ins/adoption/daily_account_activity/adoption/scans_run/impact/alerts_sent
Pagination
The Reporting API v1 paginates the responses for most endpoints. This feature addresses the issue of timeouts in API clients when trying to retrieve large volumes of records.
You can use pagination you to control the number of records you pull per request by using the following parameters:
sizecontrols the number of records that you retrieve per page; for example,{"size": 200}returns 200 records. There is no cap on the value of this parameter.pagecontrols the location, also known as offset, from which Soda retrieves the records.
For example, imagine the API can retrieve 600 records from an endpoint. When you query it with the following parameters, the response includes the first 200 records.
To retrieve all records, issue two new requests with the following parameters:
If you do not explicitly set the values for the size and page parameters, the Reporting API uses the following default values:
When a paginated endpoint returns a set of records, it also includes the following parameters:
totalindicates the number of records you can retrieve with the query.pageandsizeenable you to keep track of your location and the pages.
If you query a page that exceeds the number of records, the endpoint returns no content. For example, imagine the API can retrieve 600 records from an endpoint. The following query retrieves nothing as you have already obtained all the records and stopping at page 3 was enough.
Platform Impact: Incidents endpoint
A new endpoint, it retrieves a list of incidents users have created in Soda Cloud, along with any attributes.
Filter the results by providing a list of
dataset_idsfor which you wish to retrieve linked incidents. You can further filter results according to resolution status and time parameters.New endpoint documentation
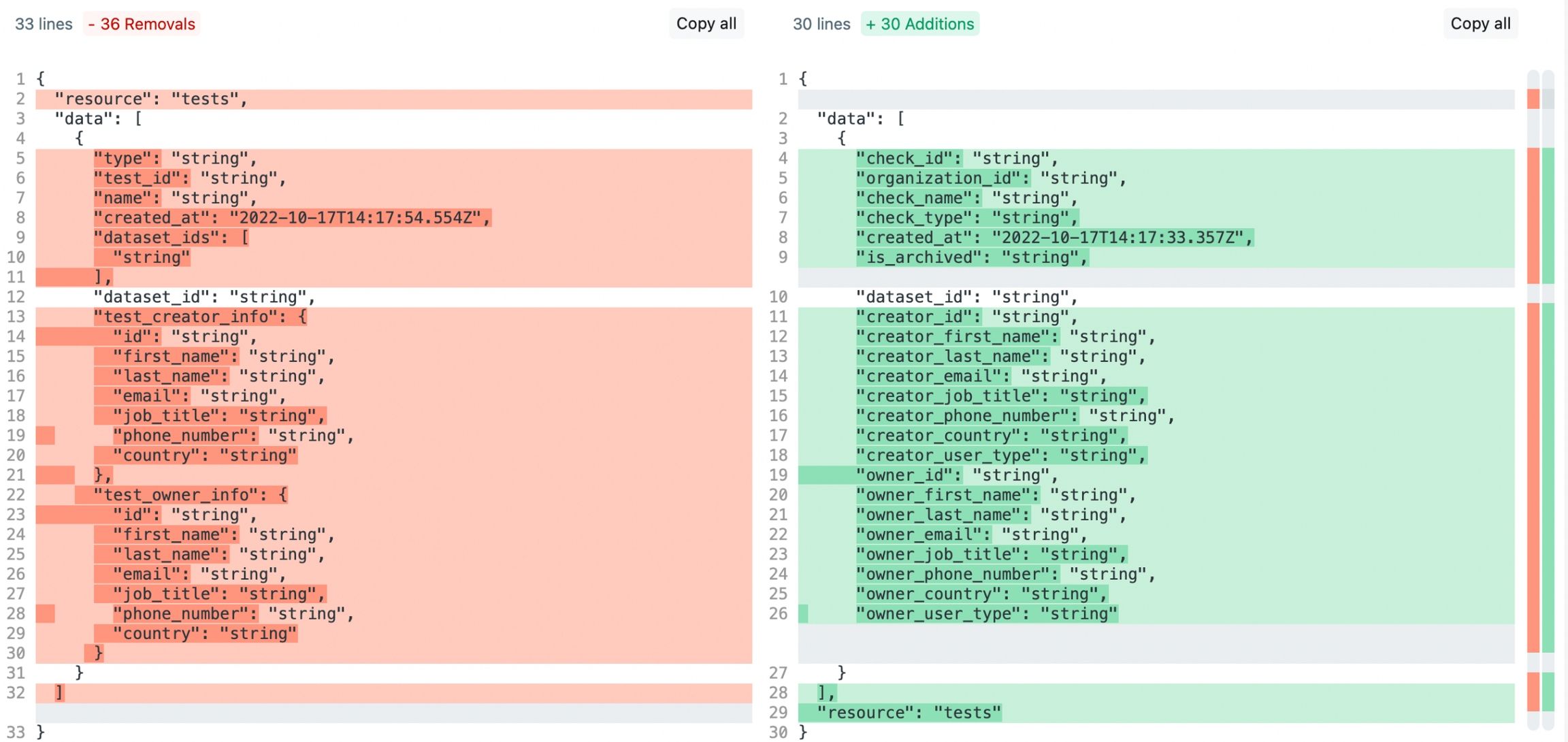
Coverage: Tests endpoint
Tests in Soda products have been renamed checks. Therefore, the endpoint previously labeled as Tests is renamed Checks.
Query checks by providing a list of
dataset_idsorcheck_idsand to get attributes about checks.The API denormalizes owner and creator information into independent fields rather than as nested objects; see image below.
New endpoint documentation
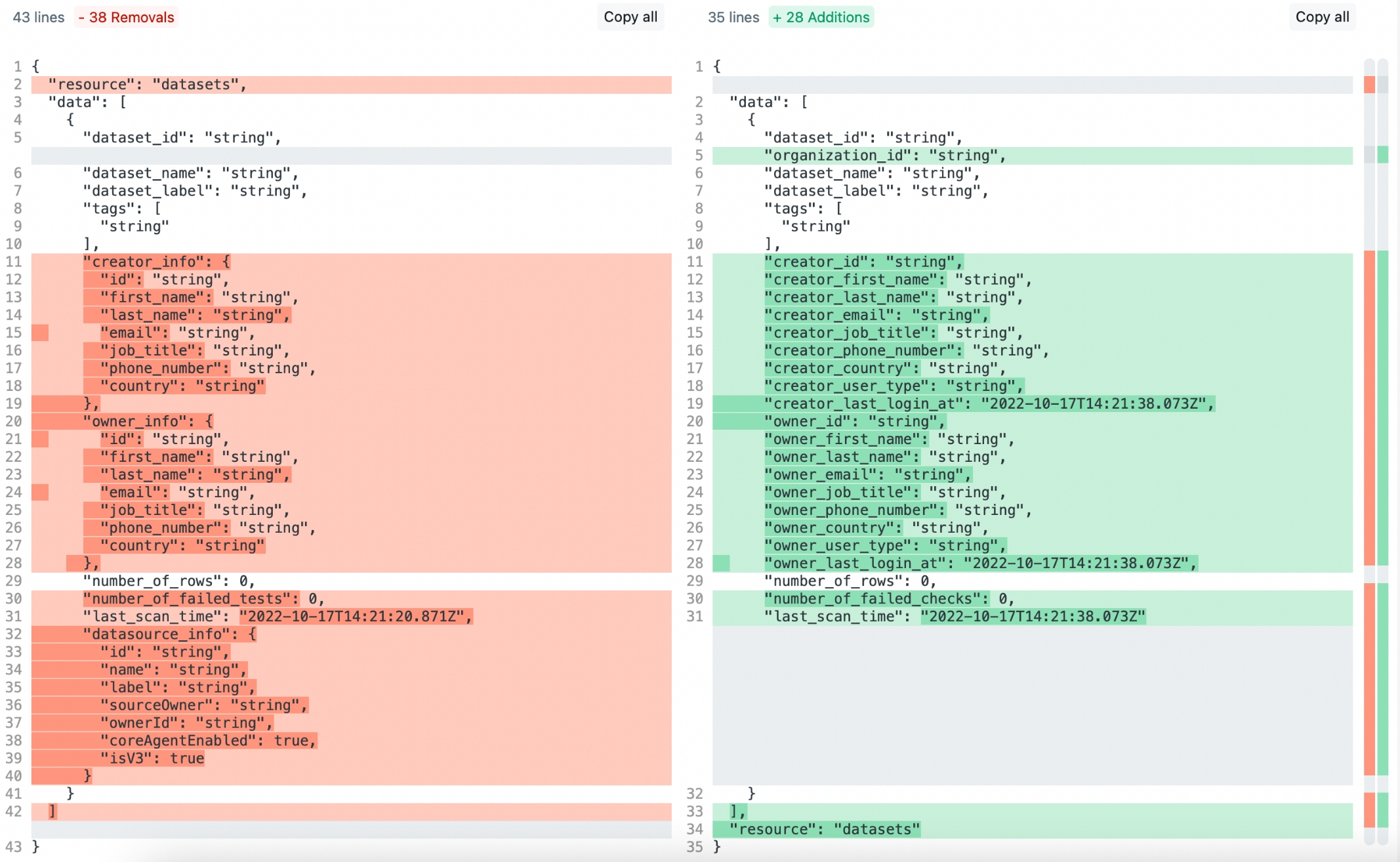
Coverage: Datasets endpoint
Provide a list of
dataset_idsto filter results, as opposed to providing a single dataset ID per request.The API denormalizes owner and creator information into independent fields rather than as nested objects; see image below.
New endpoint documentation
Coverage: Dataset coverage endpoint
Provide a list of
dataset_idsto filter results.The
include_deletedboolean was removed as the API does not store deleted datasets.New endpoint documentation

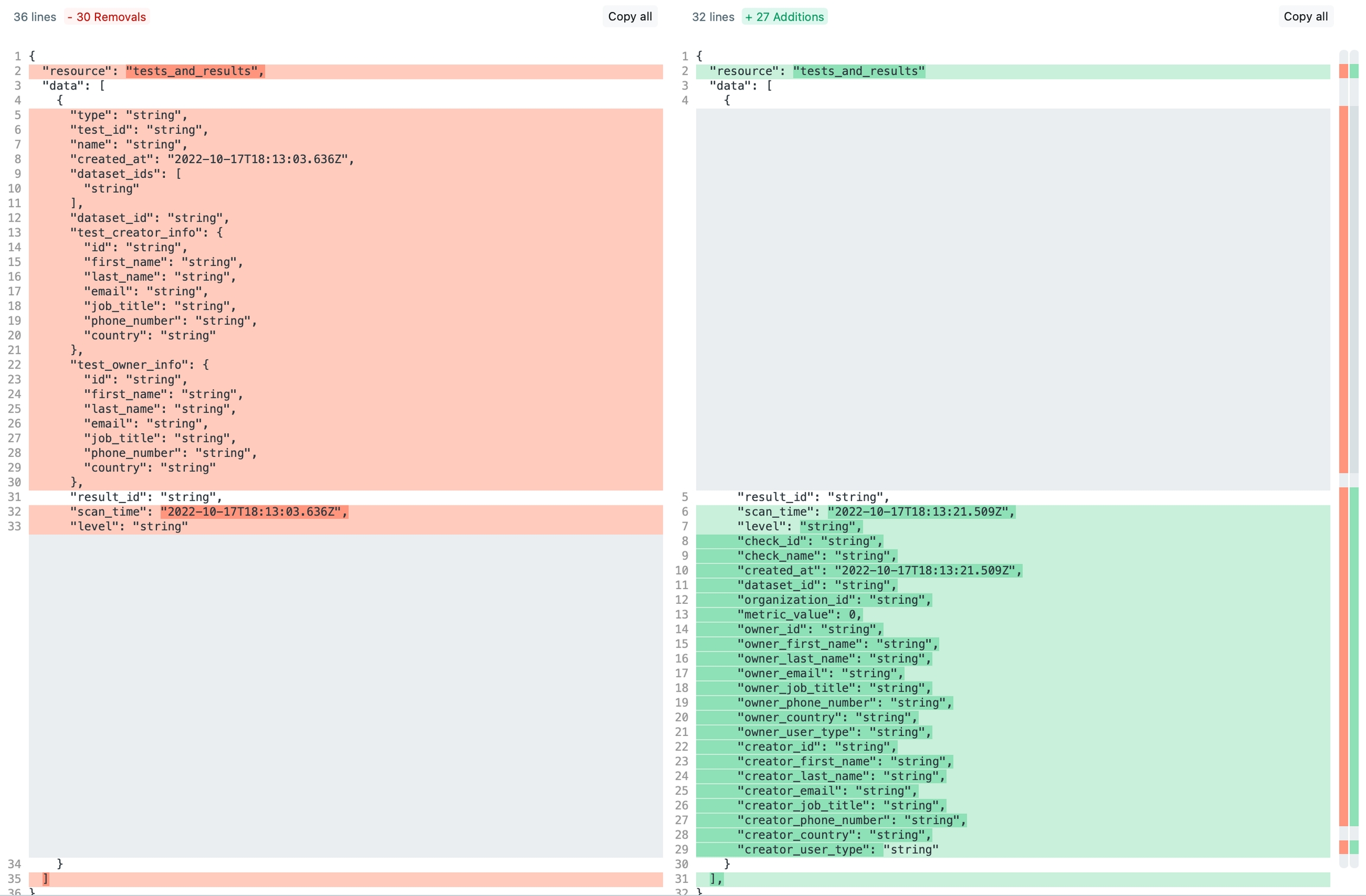
Quality: Test results endpoint
Tests in Soda products have been renamed checks. Therefore, the endpoint previously labeled as Test results is renamed Check results.
Query check results by providing a list of
dataset_idsand, optionally, afrom_datetimeISO timestamp corresponding to the moment Soda evaluated the checks as part of a scan.The API denormalizes owner and creator information into independent fields rather than as nested objects; see image below.
New endpoint documentation
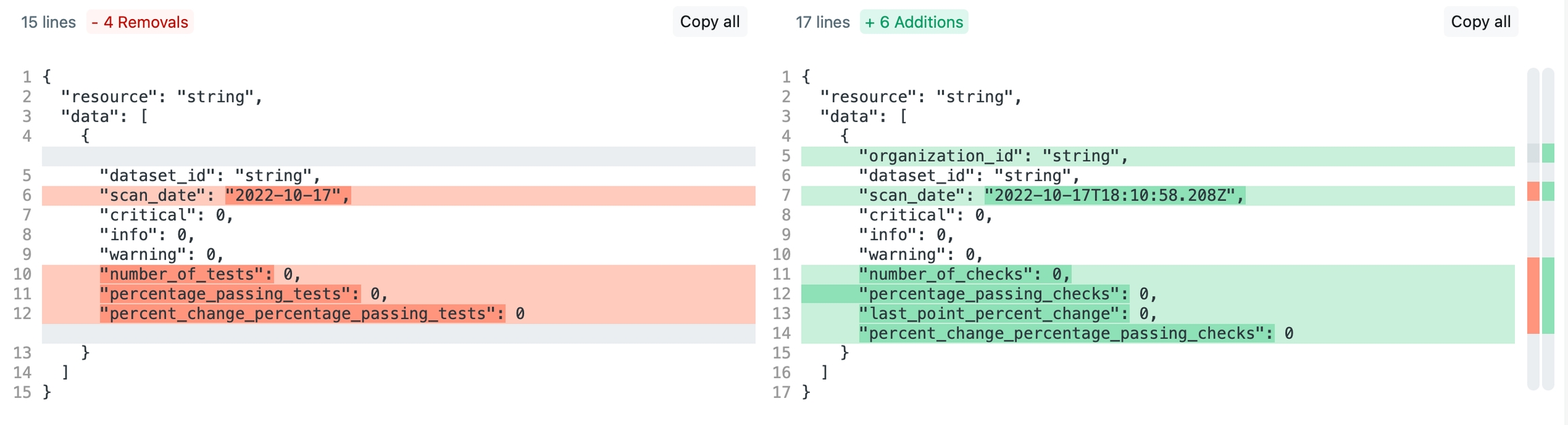
Quality: Dataset health endpoint
The endpoint accepts a list of
dataset_ids. The v0 limitation of one dataset per query does not apply in v1.The
output_all_datesboolean was removed. The API returns a row of data per day even if you have not executed a Soda scan. Optionally, you can still filter results by date using thefrom_datetimeparameter.New endpoint documentation
Last updated
Was this helpful?